AI that connects to everything. Secure in the Netherlands. From chatbot to autonomous worker.
Connect AI to your ERP, CRM and internal systems, from a secure chatbot for your team to fully autonomous AI workers. Runs on Dutch servers, open source models, fully GDPR-compliant. Plus a Dutch team of developers and consultants who build and evolve it for you.
100% Dutch servers · Open source AI · GDPR-compliant · Dutch team
They already chose IntraGPT
AI in Europe: AI Act & GDPR in practice
Why organisations deploying AI in Europe choose local, open-weight AI like IntraGPT to truly comply with the AI Act and GDPR.
- AI Act risk classification and what it means for your use cases
- GDPR & data processing: why Big Tech APIs are legally problematic
- Practical checklist for compliant AI implementation
- Why local hosting + open-weight is the only sustainable route
Why IntraGPT?
Learn moreA locally running LLM with reasoning on your own private server. Complete with chat, agents, documents, knowledge base, ISO 27001-certified security and a Dutch team guiding you every step of the way.
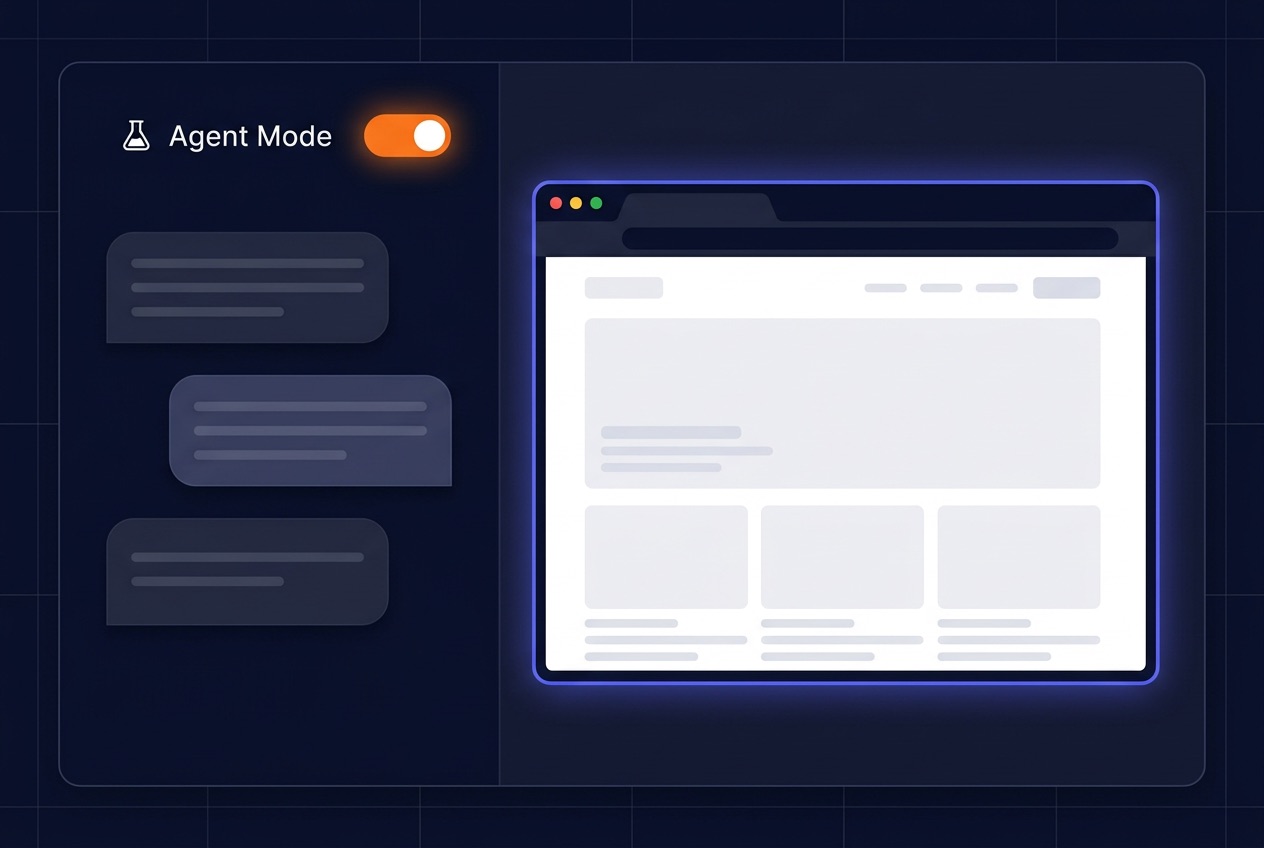
Agent Mode & Enterprise Agents
An IntraGPT agent is a digital colleague you train yourself, equip with tools and integrations, and let get work done autonomously. Not just a chatbot, but a co-worker with a job title, expertise, its own memory and access to exactly the systems you give it.
- Live Chromium browser the agent drives itself
- Word, PDF, Excel and QR codes from one prompt
- Custom agents per team with their own tools and MCP integrations
Organisations that trust us
Healthcare, logistics, finance, retail and government. Sectors where trust and results matter
“We were looking for a partner, not a tool. IntraGPT fully manages everything for us, from strategy to development. It saved us tens of thousands in external AI costs in the first quarter alone.”
“Finally a Dutch company that understands what enterprise needs. Personal contact, short lines, and a platform that just works. The ROI was visible within three months.”
“We were paying more on separate AI subscriptions than on IntraGPT. Now we have full control, governance and one point of contact. That's the difference with Big Tech.”
One platform. Four layers.
AI becomes not an experiment, but a structural part of your organisation.
The IntraGPT Platform
Everything AI needs to do within your organisation, in one controlled suite.
Consultancy
AI only works when people and processes can follow. We set that up together.
Development
When standard isn't enough, we build until it fits.
AI Department as a Service
More than software: an AI department that keeps delivering.
From assistant to digital colleague
With Agentic workflows you automate complete business processes.
Discover Agentic AIOne central intelligence layer
Feed the knowledge base with internal documents. Connect external sources. Everything becomes usable.
Enterprise security on Dutch soil
IntraGPT runs on private infrastructure in the Netherlands.
Why centralisation matters
Many organisations start with isolated AI experiments. IntraGPT centralises AI within one infrastructure layer.
Without centralisation
With IntraGPT
AI becomes manageable, scalable and controllable. One central layer across all sources.
Made for regulated sectors
IntraGPT provides the foundation where confidentiality and compliance are required.
How organisations use IntraGPT
Concrete results across different sectors. From pilot to production.
Healthcare group accelerates protocol access
A large healthcare group with 12 locations deployed IntraGPT for instant protocol access. Result: 70% less search time.
70%
Less search time
4,000+
Active users
Law firm automates contract analysis
A top-50 law firm uses IntraGPT for contract analysis and case law research. Result: 60% faster due diligence.
60%
Faster due diligence
15,000+
Contracts analysed
Supermarket chain centralises knowledge for 400 stores
A national chain with 400+ stores uses IntraGPT as central knowledge platform.
400+
Stores connected
80%
Faster procedures
Logistics company automates reporting and sales support
A B2B logistics company with 2,000 staff uses IntraGPT for sales support and reporting. Result: 50% less manual work.
50%
Less manual work
2,000
Staff reached
More than a platform
Implementing AI is an organisational question. We guide strategy, governance and risk management.
No more experiments. Just results.
AI should save your organisation money, not cost it. IntraGPT provides the foundation: platform, consultancy, development and AI department. One Dutch team standing beside you. Start with one department, see the results, and scale when you're ready.